
統計解析を行って論文やレポートを書く際、平均値や標準偏差の値だけでなく、分析結果としてt値やf値といった検定統計量であったり、有意確率や効果量といったものを報告する必要があります。
ただ、分析の出力結果には報告に必要な値以外にもたくさんの情報があり、報告の際には必要な情報だけに注意を払っていちいち手入力しないといけなかったりします。分析が5回くらいなら一つひとつやってもいいかもしれませんが、それ以上あると正直疲れます。
また、報告すべき値がやたら細かい値だと間違えてしまうリスクもあります。
そんなわけで、今回はt検定を例に統計解析結果から特定の値を取り出す方法と、それをCSVファイルに出力する手順をまとめました。
大きく分けて4つの工程にわかれます。
②代入された出力結果の中から必要な値を取り出して、別の変数に格納する
③格納された値を1つの変数にまとめる
④1つにまとめた変数をcsvファイルとして出力する。
※上記2,3は1つの工程にまとめることも可能だと思いますが今回はイメージのしやすさの観点から別の工程としてまとめました。
0.データの準備
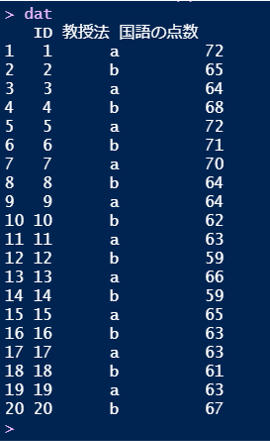
まず、以下のようなデータを変数datに代入します(データは適当に作りました)。
※同様のデータをcsvファイルとして作成してから読み込んでも問題ありません。
教授法=rep(c(“a”,”b”),times=10),
国語の点数=c(72,65,64,68,72,71,70,64,64,62,63,59,66,59,65,63,63,61,63,67))
t検定というのは二つの条件の平均値に有意な差があるかを知りたいときに使います。
例えば今回のデータであれば、教授法aを受けた人の平均点(66.2点)と教授法bを受けた人の平均点(63.9点)が有意に異なるか、というような目的のときに使われます。
このとき、教授法を独立変数、国語の点数を従属変数と呼びます。
1.分析(t検定)を行い、出力結果を変数に代入する
Rでt検定を行う際にはt.test()を使います。
今回は教授法aと教授法bには対応がない(それぞれ異なる対象者が各条件に割り当てられる)ので、対応のないt検定というものを使います。対応のないt検定の場合は,以下の式となります。
※var.equal=Fとすると,ウェルチの検定というものになります(本来は等分散性の検定をしたうえで,ウェルチの検定にするかどうかを決める必要がありますが,今回は省略してあります)。
今回のデータの場合、以下のような結果が出力されます。t検定の結果を変数res_Ttestに代入したうえで出力させてみるとt検定の結果が出てきます。
> res_Ttest
Two Sample t-test
data: dat$国語の点数 by dat$教授法
t = 1.3467, df = 18, p-value = 0.1948
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.288007 5.888007
sample estimates:
mean in group a mean in group b
66.2 63.9
2.出力結果の中から必要な値を取り出して、別の変数に格納する
ですが,不必要な情報があるとデータのコピペミスなども起こるかもしれませんので、あらかじめ必要な情報がわかっているならそれらをうまく整理できたら便利です。t検定の出力結果は、実はいくつか要素的なものを持っていて、names()で確認することができます。
[1] “statistic” “parameter” “p.value” “conf.int” “estimate” “null.value” “stderr” “alternative” “method” “data.name”
t
1.346742
$statistic
t
1.346742
自由度、t値、p値
あたりが最低限必要なので、こちらを取り出します。
> df<-res_Ttest$parameter#自由度
> p<-res_Ttest$p.value#p値
3.格納された値を1つの変数にまとめる
> res_Table
df t p
df 18 1.346742 0.1947766
>res_Table
df t p
国語の点数 18 1.346742 0.1947766
4.1つにまとめた変数をcsvファイルとして出力する。
最後に上記の内容をcsvファイルとして出力します。
csvファイルの出力は、write.csv(出力する変数, “ファイル名.csv”) という命令を打てば出力できます。
上記の関数を実行すると,以下のようなファイルが出力されます。
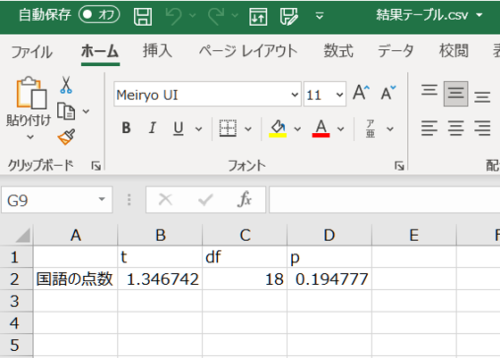
以上で報告に必要な結果だけを取り出して出力することができました。
やり方をおさらいすると以下の手順になります。
②代入された出力結果の中から必要な値を取り出して、別の変数に格納する
③格納された値を1つの変数にまとめる
④1つにまとめた変数をcsvファイルとして出力する。
なお、そのためにはfor文を使った繰り返し処理を組み合わせる必要があるのですが、その点については次回まとめたいと思います。

